สรุป course.fast.ai (part1 v4) คาบที่ 6
ในคาบนี้เราจะเรียนถึงเทคนิคในการทำ transfer learning ให้มีประสิทธิภาพ เช่น learning rate finder, freezing/unfreezing, การสร้าง dataloaders และ loss ตบท้ายด้วยการทำ recommendation system ผ่านโมเดล collaborative filtering
Learning rate finder
- เริ่มต้นจาก learning rate ต่ำๆ และ ค่อยๆ เพิ่ม learning rate ไปเรื่อยๆ และเปรียบเทียบค่า loss ในแต่ละ mini-batch
- อ้างอิงจาก เราจะเลือก learning rate ที่ค่า loss ลดลงมาด้วยความชันมากที่สุด (ประมาณ learning rate จาก จุดที่ loss ต่ำที่สุด / 10)
- ตัวอย่าง code สำหรับการหาค่า learning rate จาก object Learner
learn = cnn_learner(dls, resnet34, metrics=error_rate)
lr_min,lr_steep = learn.lr_find()
Unfreezing and transfer learning
- Model CNN ประกอบไปด้วยหลายๆ layer ต่อๆกัน โดยแต่ละ layer ประกอบกันขึ้นมาจาก linear function และ non-linear activation function อีกที
- Layer ต้นๆ ของ model CNN ที่ถูก train มาจากข้อมูลรูปภาพขนาดใหญ่อย่าง ImageNet จะเรียนรู้ รูปแบบ (pattern) พื้นฐาน ของรูปภาพ ในขณะที่ layer ท้ายๆ จะเรียนรู้รูปแบบที่มีความซับซ้อน และเจาะจงกับชุดข้อมูลรูปภาพที่ model ถูก train มา มากกว่า
- การทำ transfer learning หรือการเรียนรู้จาก model ที่เรียนรู้จากข้อมูลขนาดใหญ่มาแล้ว และมาปรับใช้ (fine tuning) กับข้อมูลชุดเล็กกว่า ใน domain ที่แตกต่างกัน จึงจำเป็นต้องใช้รูปแบบพื้นฐานที่ layer ต้นๆ ของ model CNN ถูก train มา มากกว่า รูปแบบที่เจาะจง หรือจำเพาะกับชุดข้อมูลที่ layer ท้ายๆ ของ model ได้เรียนรู้มา
- ขั้นตอนการทำ transfer learning ด้วยการ fine tuning model CNN ที่เรียนรู้จากข้อมูลขนาดใหญ่มาแล้ว
- train model CNN เฉพาะ layer ของ classifier และ freeze weight ของ layer ก่อนหน้าไว้ทั้งหมด (ไม่ทำการ update ค่า weight) ด้วยจำนวน epoch น้อยๆ (1-3 epoch) เพื่อปรับจูนค่า weight ใน layer ของ classifier กับข้อมูลชุดใหม่ก่อน โดย default object Learner ที่ถูกสร้างขึ้นมาจาก architecture ของ model CNN ที่กำหนด จะ freeze weight ของ layer ส่วนที่เป็น deep convolutional network ไว้อยู่แล้ว
learn = cnn_learner(dls, resnet34, metrics=error_rate)
learn.fit_one_cycle(3, 3e-3)
- unfreeze weight ในส่วนของ deep convolutional network (layer ก่อนหน้า classifier) เพื่อทำ fine tuning ในส่วนนี้
learn.unfreeze()
-
หา learning rate ที่เหมาะสมสำหรับ fine tuning deep convolutional network ใหม่ เนื่องจาก weight ของ model CNN ถูกปรับมาจากการเรียนรู้ในขั้นตอนที่ 1 แล้ว ทำให้ learning rate ที่เหมาะสมในขั้นตอนนี้จะไม่เหมือนขั้นตอนที่ 1
-
ทำการ fine tuning ในขั้นตอนสุดท้าย จาก learning rate ที่ได้จากขั้นตอนที่ 3 โดยในขั้นตอนนี้ fastai จะใช้เทคนิคที่เรียกว่า discriminative learning rate คือ กำหนด learning rate ของ deep convolutional network แตกต่างกัน โดยกำหนดให้ learning rate ใน layer ต้นๆ น้อยกว่า learning rate ใน layer ท้ายๆ เพื่อสอดคล้องกับรูปแบบพื้นฐาน และ รูปแบบเจาะจง ที่ layer ต้นๆ และ layer ท้ายๆ ได้เรียนรู้มา ตามลำดับ
นอกเหนือจากการใช้เทคนิค disscriminative learning rate โดยใช้ function slice ใน argument lr_max lr_max=slice(1e-6, 1e-4) (ใช้ learning rate 1e-6 กับ layer ต้นๆ และเพิ่มเป็น 1e-4 กับ layer ท้ายๆ) fastai ยังใช้เทคนิคการ train ด้วย one cycle learning rate หรือ กำหนดให้ learning rate ในแต่ละ iteration ไม่เท่ากัน โดยเริ่มต้นจาก learning rate ที่ค่อยๆ เพิ่มสูงขึ้นถึง แล้วจึงค่อยๆ ลดลงต่ำกว่า learning rate เริ่มต้นในตอนแรก เพื่อเป็นการ warm up ในช่วงแรก แล้วจึงค่อยๆ เข้าสู่จุดที่ weigt ของ model เริ่มเสถียรด้วยการลด learning rate ลง
learn.fit_one_cycle(12, lr_max=slice(1e-6,1e-4))
Deeper architecture
- เราสามารถเพิ่ม capacity/ performance ของโมเดล ด้วยการใช้ model architecture ที่มีขนาด layer ที่ลึกขึ้น เช่น model ResNet 18 -> 34 -> 50 -> 101 -> 152 แต่ในขณะเดียวกัน model ที่มีขนาดใหญ่ขึ้นก็จะมาพร้อมกับ memory footprint ที่มากขึ้น และ computation cost/ time ที่สูงขึ้น
Multi-label classification
การทำ multi-label classification คือ การทำนายที่มี label กำกับข้อมูลได้มากกว่า 1 class เช่น รูปภาพที่ประกอบไปด้วยวัตถุหลายๆ อย่างในภาพเดียวกัน เช่น ภาพคนขี่จักรยาน
- เราจะใช้ข้อมูลชุด
PASCALสำหรับศึกษาการทำ multi-label classification - ตัวอย่างข้อมูลสำหรับทำ multi-label classification
DataBlock
ในขั้นตอนนี้ เราจะเปลี่ยนข้อมูลที่อยู่ในรูปแบบของ pandas DataFrame ให้อยู่ในรูปแบบของ class DataLoaders ของ fastai เพื่อ train model
เนื่องจาก fastai ถูกสร้างขึ้นมาจาก library PyTorch ดังนั้น เราจะมาทำความเข้าใจการเตรียมข้อมูลสำหรับ train model ด้วย library PyTorch ก่อน ซึ่งจะใช้ 2 class หลักๆ ต่อไปนี้
DataSet: ทำหน้าที่เป็น collection ของข้อมูล ทำหน้าที่ return tuple ของ independent variable (feature) และ dependent variable (target) โดยสามารถเข้าถึงข้อมูลเหล่านี้ได้ผ่าน index ของ collectionDataLoader: iterator ที่ทำหน้าที่ return mini-batch ของข้อมูล โดยแต่ละ mini-batch หมายถึง tuple ของ independent variable และ dependent variable หลายๆ ชุด
ในส่วนของ fastai จะใช้ 2 class หลักๆ ดังต่อไปนี้ สำหรับเตรียมข้อมูลสำหรับ train model
DataSets: สร้าง object ที่ประกอบด้วย trainingDataSetและ validationDataSetDataLoaders: สร้าง object ที่ประกอบด้วย trainingDataLoaderและ validationDataLoader
โดยขั้นตอนในการสร้าง DataLoader จะเริ่มต้นจาก DataSet ใน PyTorch และเช่นเดียวกัน กับขั้นตอนในการสร้าง DataLoaders จะเริ่มต้นจาก DataSets ใน fastai
เราจะใช้ DataBlock สำหรับการเตรียม DataLoaders อย่างเป็นขั้นตอนใน fastai
- ลำดับแรก เราจะกำหนด function สำหรับการเข้าถึง independent variable และ dependent variable จาก
DataFrameผ่าน argumentget_xและget_yในDataBlockตามลำดับ
function get_x จะ return path สำหรับเข้าถึงแต่ละรูปภาพ โดยการนำ column fname มาต่อกับ path สำหรับเข้าถึง file รูปภาพ
function get_y จะ return list ของ label ของแต่ละรูปภาพ ที่สามารถมีได้หลาย label ในการจำแนกรูปภาพแบบ Multi-label classification โดยการนำ string จาก column labels มา split ด้วย white space (‘ ‘)
def get_x(r): return path/'train'/r['fname']
def get_y(r): return r['labels'].split(' ')
dblock = DataBlock(get_x = get_x, get_y = get_y)
dsets = dblock.datasets(df)
- ลำดับถัดไปเราจะเปลี่ยนจาก path รูปภาพ ให้เป็น tensor ผ่าน argument
blocksซึ่งจะรับ block ชนิดต่างๆ ตามลักษณะข้อมูลที่เราต้องการ output ออกมา โดยเราจะใช้ImageBlockและMultiCategoryBlockสำหรับ output tensor จาก path รูปภาพ และ แปลง list ของ label ให้เป็น tensor ตามลำดับ (สำหรับการทำ image classification ที่มี class เดียวต่อรูปภาพ เราจะใช้CategoryBlockแทนMultiCategoryBlock)dblock = DataBlock(blocks=(ImageBlock, MultiCategoryBlock), get_x = get_x, get_y = get_y) dsets = dblock.datasets(df) - เราจะกำหนดการแบ่งข้อมูล train และ validation ผ่าน argument
spiltterโดยกำหนด functionsplitterที่ return train และ validationDataFrameโดยใช้ columnis_validที่ให้มา สำหรับแยกข้อมูล train และ validation ``` def splitter(df): train = df.index[~df[‘is_valid’]].tolist() valid = df.index[df[‘is_valid’]].tolist() return train,valid
dblock = DataBlock(blocks=(ImageBlock, MultiCategoryBlock), splitter=splitter, get_x=get_x, get_y=get_y)
dsets = dblock.datasets(df)
- ขั้นตอนสุดท้าย เราจะกำหนดการทำ transformation กับ tensor รูปภาพ เพื่อให้ ขนาดของ tensor แต่ละรูปภาพมีขนาดเท่ากัน โดยใช้ object จาก `RandomResizedCrop` ใน argument `item_tfms`
dblock = DataBlock(blocks=(ImageBlock, MultiCategoryBlock), splitter=splitter, get_x=get_x, get_y=get_y, item_tfms = RandomResizedCrop(128, min_scale=0.35)) dls = dblock.dataloaders(df)
## Binary Cross Entropy
ในขั้นตอนถัดไป หลังจากสร้าง `DataLoaders` เรียบร้อยแล้ว เราจะสร้าง `Learner` สำหรับ train model และ กำหนด loss function และ กำหนด metric เพื่อวัดผล model
เราจะใช้ binary cross entropy loss ซึ่งรับค่า input จาก logit หรือ activation จาก layer สุดท้ายของ neural network (ขนาดเท่ากับจำนวน class ที่ต้องการทำนาย) ซึ่งเป็นตัวเลขที่ยังไม่ถูก scale ให้อยู่ในช่วง ระหว่าง 0 กับ 1 หรือยังไม่ถูกเปลี่ยนให้เป็น probability ของแต่ละ class มาเข้า `sigmoid` activation function เพื่อสเกลค่า และ คำนวณค่า loss จาก -log ของผลต่างระหว่าง target probability กับ probability ที่ model ทำนาย แล้วจึงหาค่าเฉลี่ยจากค่า loss ของแต่ละ class ดังนี้
def binary_cross_entropy(inputs, targets): inputs = inputs.sigmoid() return -torch.where(targets==1, 1-inputs, inputs).log().mean()
อย่างไรก็ตาม fastai จะเลือกใช้ loss function ดังกล่าวโดยอัติโนมัติ เมื่อเราใช้ `DataLoader` ที่ output dependent variable ด้วย `MultiCategoryBlock`
เราจะใช้ `accuracy_multi` เป็น metric สำหรับการทำ multi-label classification โดยใช้ function `partial` ของ python เพื่อกำหนดค่า threshold ของ probability เพื่อทำนายว่ารูปภาพมี หรือไม่มี class นั้นๆ อยู่ในรูปภาพ (ค่า default ที่ 0.5) ดังนี้
learn = cnn_learner(dls, resnet50, metrics=partial(accuracy_multi, thresh=0.2)) learn.fine_tune(3, base_lr=3e-3, freeze_epochs=4)
โดยเราจะเลือก probability/ prediction threshold ที่ดีที่สุด โดยดูจาก plot ระหว่างค่า accuracy และ ค่า threshold ต่างๆกัน
![รูปภาพ accuracy x thd]()
## Image Regression
เราสามารถทำ transfer learning เกี่ยวกับการทำ regression ในข้อมูลรูปภาพ เช่น การทำ head pose estimation (นายพิกัดของศีรษะจากรูปภาพ) โดยในพาร์ทนี้เราจะใช้ชุดข้อมูล ["Biwi Kinect Head Pose dataset"]("https://icu.ee.ethz.ch/research/datsets.html") เพื่อลองทำ transfer learning กับ head pose estimation
เราจะใช้ function `get_image_files` เพื่อเข้าถึง path ของรูปภาพ แต่ละภาพ ตาม path ที่กำหนด ส่วน dependent variable หรือ head pose ของแต่ละรูปภาพ จะถูกเก็บไว้ใน file ที่ลงท้ายด้วย prefix `pose` ด้วย function `img2pose`
img_files = get_image_files(path) def img2pose(x): return Path(f’{str(x)[:-7]}pose.txt’)
เราจะแปลงข้อมูลที่อ่านจาก file ที่อ่านจาก `*pose.txt` ด้วย function `get_ctr` เพื่อให้ได้ head pose ออกมาเป็นพิกัดในรูปภาพ
cal = np.genfromtxt(path/’01’/’rgb.cal’, skip_footer=6) def get_ctr(f): ctr = np.genfromtxt(img2pose(f), skip_header=3) c1 = ctr[0] * cal[0][0]/ctr[2] + cal[0][2] c2 = ctr[1] * cal[1][1]/ctr[2] + cal[1][2] return tensor([c1,c2])
เราจะกำหนด `DataBlock` สำหรับ train model โดยใช้ `PointBlock` ใน argument ที่สอง ของ `blocks` เพื่อกำหนดว่า independent variable ของเราจะเป็นตัวแปรประเภท continuous ดังนี้
biwi = DataBlock( blocks=(ImageBlock, PointBlock), get_items=get_image_files, get_y=get_ctr, splitter=FuncSplitter(lambda o: o.parent.name==’13’), batch_tfms=[aug_transforms(size=(240,320)), Normalize.from_stats(imagenet_stats)] )
สำหรับขั้นตอน train model เราสามารถกำหนด output range ในการทำ regression ผ่าน argument `y_range` ใน object จาก class `Learner` ซึ่งจะ scale ค่า output ให้อยู่ในช่วงที่กำหนด โดยใช้ function `sigmoid_range` อีกที
def sigmoid_range(x, lo, hi): return torch.sigmoid(x) * (hi-lo) + lo learn = cnn_learner(dls, resnet18, y_range=(-1,1))
สำหรับขั้นตอนที่เหลือ ได้แก่ การหา learning rate ที่เหมาะสม และ ทำ transfer learning ด้วยการ fine tuning CNN model
learn.lr_find()
let say an LR was found at 1e-2
lr = 1e-2 learn.fine_tune(3, lr)
# Collaborative Filtering
การเรียนรู้คุณลักษณะ (latent factor) ของ user และ item ผ่าน ข้อมูล interaction ระหว่าง user และ item ยกตัวอย่างเช่น ข้อมูลการให้ rating หนังของผู้ใช้งานบน website IMDB หรือ ข้อมูลการซื้อสินค้าของลูกค้าบน platform e-commerce เพื่อสร้างระบบแนะนำ item ที่คล้ายๆ กับ item ที่ user เคยมี interaction ด้วย (เคยให้เรทติ้ง, เคยซื้อ, หรือ เคยคลิก)
ในบทนี้เราจะเรียนรู้การสร้าง recommendation system ด้วยเทคนิค collaborative filtering ด้วยชุดข้อมูล MovieLens
เมื่อเรานำข้อมูล rating ที่ user แต่ละคนให้กับหนังแต่ละเรื่องที่ดู มาแสดงในลักษณะตารางที่กำหนด row index และ column index ด้วย userId และ MovieId ตามลำดับ และ ให้แต่ละช่อง เป็น rating ที่ user ให้คะแนน movie ที่เคยดูมาแล้ว จะมีลักษณะดังภาพด้านล่าง

latent factor ของ user แต่ละคน และ movie แต่ละเรื่องจะถูก initialize โดยการสุ่มค่า ก่อนเริ่มต้น train model โดยเราจะกำหนดขนาดของ latent factor ของ user และ movie ให้มีขนาดเท่ากัน เนื่องจากเราจะคำนวณ rating ที่ user ให้กับแต่ละ movie โดยใช้ dot product ระหว่าง latent factor ของ user และ movie
เราสามารถใช้ MSE loss เพื่อคำนวณ error ระหว่าง rating ที่คิดมาจาก dot product ระหว่าง latent factor ของ user และ movie และ rating จาก label ข้อมูล โดยใช้วิธีการ SGD เพื่อ update ค่า latent factor เหล่านี้ให้ได้ค่า MSE loss ที่ต่ำๆ
> dot product: เป็น operation ระหว่างสอง vector ที่มีขนาดเท่ากัน คิดโดยการรวมผลคูณของแต่ละ element จากทั้งสอง vector เช่น dot([0.98, 0.9, -0.9], [0.9, 0.8, -0.6]) -> 0.98 * 0.9 + 0.9 * 0.8 + -0.9 * -0.6
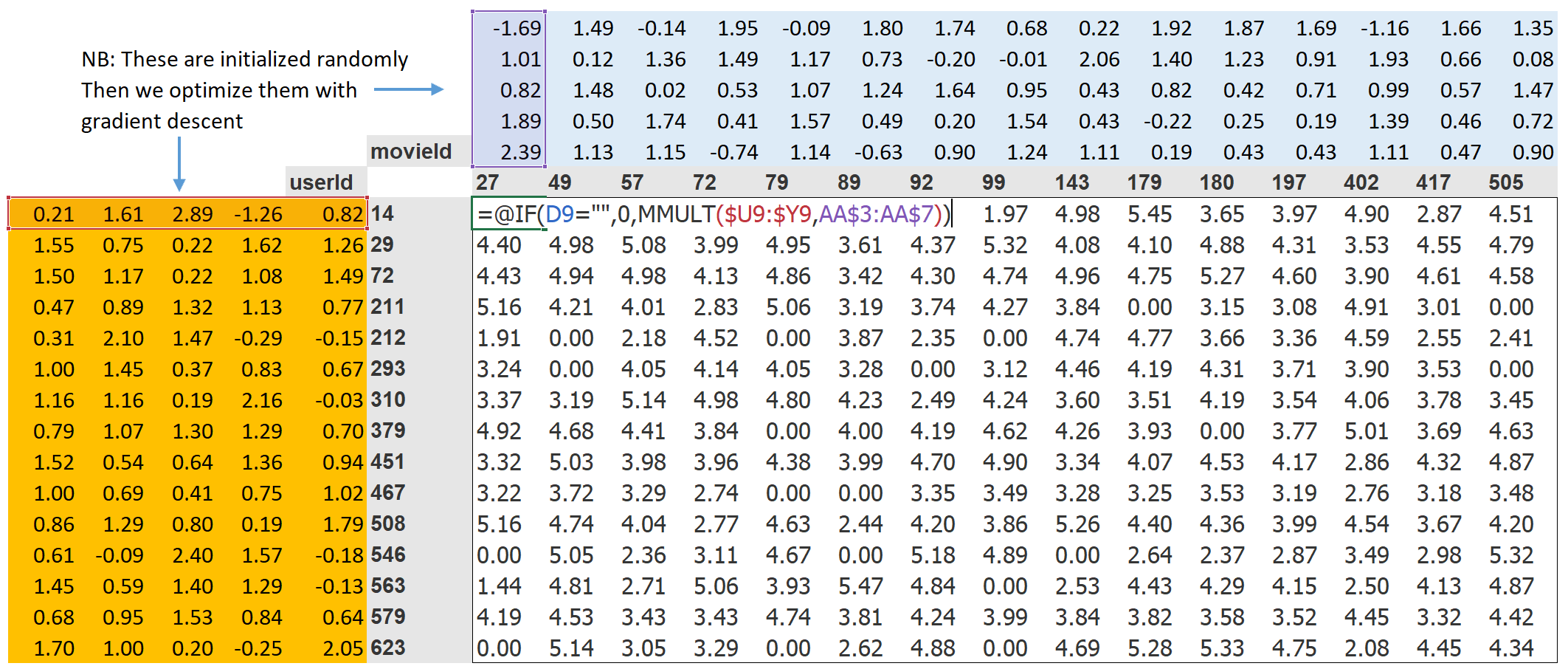
ในการคำนวณ dot product ระหว่าง latent factor ของ user และ movie จะต้องมีการเข้าถึง matrix ที่เก็บค่า latent factor ของ user หรือ movie ทุกๆ id ไว้ โดยใช้ index อย่างไรก็ตาม operation ในการ train model deep learning จะจำกัดอยู่เพียงแค่การบวก/คูณ matrix และ การใช้ activation function ต่างๆ เท่านั้น ดังนั้นแทนที่จะเข้าถึง latent vector โดยใช้ index ตรงๆ เราจะใช้ one-hot-encoded-vector ซึ่งเป็น vector ที่มีค่าเท่ากับ 1 ณ ตำแหน่งของ index ที่ต้องการ นอกจากตำแหน่งนี้ กำหนดค่าให้เป็น 0 ทั้งหมด และ กำหนดขนาดของ one-hot-encoded-vector ให้เท่ากับขนาดของ index
ตัวอย่างการเข้าถึง latent factor ของ user ที่ index = 3 จาก latent matrix ของ user
n_users = len(dls.classes[‘user’]) n_movies = len(dls.classes[‘title’]) n_factors = 5
user_factors = torch.randn(n_users, n_factors) movie_factors = torch.randn(n_movies, n_factors)
one_hot_3 = one_hot(3, n_users).float()
access using one hot encoded vector
user_factors.t() @ one_hot_3
this is equivalent to
user_factors[3]
เทคนิคดังกล่าวนี้ในการเข้าถึง latent vector ด้วย index ผ่านวิธีการแบบเดียวกันกับการคูณ latent matrix ด้วย one-hot-encoded-vector สามารถทำได้โดยใช้ layer ที่เรียกว่า embedding ใน deep learning library ส่วนใหญ่ รวมถึง Pytorch
## Creating DataLoaders
ก่อนจะสร้าง และ train model เราจำเป็นจะต้องสร้าง `DataLoaders` จากข้อมูลที่อยู่ในรูป `DataFrame` ของ pandas ขึ้นมาก่อน โดยเราจะอ่านไฟล์การให้ rating movie ของแต่ละ user มาจาก ไฟล์ `u.data` และ ข้อมูล movie แต่ละเรื่องจาก ไฟล์ `u.item`
เราจะ join ข้อมูล rating และ movie ด้วย method `merge` ใน `DataFrame` เพื่อรวมชื่อหนังเข้ากับ variable `rating` และ สร้าง `DataLoader` โดยใช้ method `from_df` จาก class `CollabLoaders` ของ fastai
ratings = pd.read_csv(path/’u.data’, delimiter=’\t’, header=None, names=[‘user’,’movie’,’rating’,’timestamp’])
movies = pd.read_csv(path/’u.item’, delimiter=’|’, encoding=’latin-1’, usecols=(0,1), names=(‘movie’,’title’), header=None)
ratings = ratings.merge(movies)
dls = CollabDataLoaders.from_df(ratings, item_name=’title’, bs=64)
## Collaborative filtering from scratch
ในขั้นตอนนี้เราจะเขียน model สำหรับการทำ collaborative filtering โดยใช้ Pytorch ซึ่งเราสามารถนำ model ที่่สร้างขึ้นมาดังกล่าวมา train ด้้วย object จาก class `Learner` ของ fastai ได้
การสร้าง model โดยใช้ Pytorch จะยึดหลักการเขียนโปรแกรม object-orientend programming (OOP) โดยเราจะสร้าง class ของ model ที่ inherit มาจาก class `Module` ของ Pytorch โดยหลักๆ เราจะต้องเขียน method `__init__` สำหรับกำหนดค่าเริ่มต้น และ layer หรือ module ต่่างๆ ของ model และ method `forward` สำหรับกำหนดว่า model จะ return output tensor จาก input tensor เวลาเราเรียกใช้งาน model อย่างไร
จะเห็นว่าใน method `__init__` เรากำหนด `user_factors`, `user_bias`, `movie_factors`, `movie_bias` โดยใช้ layer `Embedding` จาก Pytorch
โดย `user_factors` และ `movie_factors` คือ latent matrix ของ user และ movie ตามลำดับ ขนาดเท่ากับ จำนวนของ user หรือ movie * ขนาดของ latent vector (`n_factors`)
`user_bias` และ `movie_bias` คือ ค่า bias ของ user และ movie แต่ละ index ตามลำดับ
ค่า `y_range` จะใช้สำหรับ scale ค่า output ของ model ให้อยู่ในช่วงคะแนน rating ของ movie โดยมีการกำหนดค่าเผื่อไว้เล็กน้อย (y_range=(0,5.5) ในขณะที่ rating อยู่ในช่วง 0-5)
ใน `forward` model จะรับ input tensor ผ่านตัวแปร `x` ซึ่งจะให้ค่า index ของ user และ movie ออกมา เราจะใช้ index ดังกล่าวในการเข้าถึง latent vector ของ user และ movie ในข้อมูลแต่ละ batch จาก `DataLoader` และคำนวณ rating จาก dot product ระหว่าง latent vector ทั้งสอง รวมกับค่า bias ของ user และ movie แล้วจึง scale ด้วย function `sidmoid_rage` ก่อนออกมาเป็น rating ที่คำนวณจาก model
class DotProductBias(Module): def init(self, n_users, n_movies, n_factors, y_range=(0,5.5)): self.user_factors = Embedding(n_users, n_factors) self.user_bias = Embedding(n_users, 1) self.movie_factors = Embedding(n_movies, n_factors) self.movie_bias = Embedding(n_movies, 1) self.y_range = y_range
def forward(self, x):
users = self.user_factors(x[:,0])
movies = self.movie_factors(x[:,1])
res = (users * movies).sum(dim=1, keepdim=True)
res += self.user_bias(x[:,0]) + self.movie_bias(x[:,1])
return sigmoid_range(res, *self.y_range) ```
เราจะ train model DotProductBias ด้วย Learner จาก fastai โดยใช้ loss function จาก MSELossFlat
model = DotProductBias(n_users, n_movies, 50)
learn = Learner(dls, model, loss_func=MSELossFlat())
learn.fit_one_cycle(5, 5e-3)
ตอบคำถามท้ายบทได้ที่ aiquizzes